在ChatGPT领域,哪个方向是它的未来趋势,能更快地“接近真相”呢?本文作者从商业的角度,对7个方向进行了总结分析,希望能给你带来一些启发。

小科普:尤里卡,希腊词汇,是发现真相时的感叹词,在游戏文明6中,当你触发尤里卡,你的科技会缩短40%的研究时间(中国文明缩短50%)
再小科普:AI绘画的尤里卡时刻有两个,Stable Diffusion让成本下降到可用,ControlNet让绘画可控性大大提升,踏入更广阔的应用领域。
在前面的系列文章中,我们讲了LLM的技术原理、商业应用、社会影响等方面。但这些都是聚焦当下或较近的未来,那么更遥远的趋势呢?
就像Diffusion的ControlNet模型一样,如果你更早发现他的趋势,你就不会花费精力在语义理解、稳定控制等方面,而是直奔可控性(我与很多朋友聊天,发现他们的团队或多或少都有可控性方面的尝试,但因为趋势错判,而没有全力All IN)。
或者哪怕你不是做技术的,你提前预判到,你也能在产品角度、商业角度做前置的思考和布局。
不过接下来我的分析不会那么偏技术(因为不懂),而是从更商业的角度来看这些方向。毕竟商业利益催生应用,应用催生技术涌现,有时候跳出技术思维(刚好我没有),或许更能看到一些盲生的华点。
希望对大家有所启发,也欢迎拍砖讨论。
以下是全部内容:
- 降低门槛 ⭐️⭐️
- 万物终端 ⭐️⭐️⭐️
- 思维链CoT ⭐️⭐️
- 反作弊 ⭐️
- 文本外应用 ⭐️
- 私有化 ⭐️⭐️
- GPT4来了?⭐️⭐️⭐️
下面每个方向的介绍都比较简洁,不会穷举所有案例,也不会长篇大论讲解原理。
方向一:降低门槛 ⭐️⭐️
我说过技术涌现是需要“人数基础”的,参与的玩家越多,这个领域的发展才会越快。同时我们本身也需要关注门槛的降低速度,以预判更多玩家涌入对商业生态的影响。基于这两个因素,重要性2星。
第一个例子以FlexGen为例,目前GitHub 5K Stars,实现了大模型推理中的显卡平替(推理就是回答问题)。
简单介绍:
1)用更大的吞吐量掩盖低延迟(你可以慢,但做多一点);
2)工程上优化了效率,不仅可以用16GB T4 的显卡去替代又贵又稀缺的80G A100。并且实现了这种方式相较以往框架的100倍效率提升。——说白了,推理的时候你不一定要用A100了!喜大普奔!
如果需要比较通俗的科普,看这个:https://zhuanlan.zhihu.com/p/608279479如果需要看GitHub原链接,看这个:https://github.com/FMInference/FlexGen
第二个例子是ColossalAI(看名字就知道,专门对付大模型),Github上17.5K Stars,他在解决训练成本、推理成本的问题。他的实现方案太复杂了,大概是更高效的并发策略、更好的工程结构等我还没深入研究的东西哈哈。大家感兴趣follow下面链接做深入学习。科普性报道(可能有PR成分)如下:https://zhuanlan.zhihu.com/p/606397774GitHub链接如下:https://github.com/hpcaitech/ColossalAI#GPT-3
第三个例子是各类开源组织,例如EleutherAI(Stable Diffusion,GPT-3的开源组织),LAION(数据开源组织)等,他们对模型或者对数据的开源,推动了更多参与者加入这个方向的研究。
整体来看,有非常多关于降低门槛方面的努力,包括模型开源、模型优化、工程优化、算力降低、显卡平替等,说不定有一些我没发现但正在进行中的(例如定制芯片、稀疏化模型等等)。
方向二:万物终端 ⭐️⭐️⭐️
我们现在使用ChatGPT可以让帮我们生成视频脚本,甚至按API字段要求生成一个可执行的入参命令。但是这种生成永远停留在文字程度,我们要做最终的生产,只能自己打开其他的应用(如PS、如其他APP的API接口)才能将生成结果转变为最终产物。
如果ChatGPT能够使用工具呢?当我让他帮我收集海外SaaS公司2022年财报,他将结果整理为列表,同时标识引用的财报PDF,并将PDF下载到我的桌面(且新建文件夹并自动重命名)。你觉得如何?想要吗?
甚至更复杂一点(短期不太现实哈哈),你跟他说帮我画一张“醉后不知天在水,满船星梦压清河”的水墨画(用AI绘画),并在右上角用草书写上这两句古诗(用PS)。你想要吗?
这将是颠覆式的开始,就像当初IOS诞生一样,围绕一个终端,全世界的应用都会按照他的标准接入,并涌现出无穷的智慧。GPT不再是一种工具,而是新时代人人都离不开的终端——替代手机/电脑,更强大的虚拟终端。
在这种刺激下,巨头对LLM的争夺会进入一个更剧烈的,更白热化的阶段:新时代的诺亚方舟,不上船者必死。
这一切的开始,来自Meta AI发布的Toolformer,他让LLM连接工具成为可能。
简单介绍:
1. 让AI明确有些问题,可以调用工具(例如知识,计算,查询日程);
2. 让AI合理地转化自然语言命令为API命令(即调用工具的入参);
3. 让AI在组织回答时,正常回答,但部分需获取的答案,去调用API获得结果后再嵌入回答中。
下面是一个论文中的例子(括号内即API命令+调用后的结果):
Q:拜登在哪里出生
A:拜登在(调用搜索引擎查询“拜登在哪里出生”,获得答案斯克兰顿)斯克兰顿出生。当然论文中的例子还较为简单,离我的狂想还有一段距离。但这种思路揭示了一种未来:我们可以训练LLM模型对工具使用的理解,包括何时应该使用工具,自然语言如何转化为使用工具的API命令。
等他进一步完善之后,所有的应用都必须按照LLM定义的标准提供接口,并跪着求LLM收录他们作为可调用工具(例如都是查询日历行程,我是查Google日历,还是查滴答清单呢?)
科幻未来就在眼前,三星好评!
简单科普看这个:https://www.zhihu.com/question/583924233/answer/2900129018论文看这个:https://arxiv.org/pdf/2302.04761.pdf
方向三:思维链CoT ⭐️⭐️
第一个例子有点搞笑,但我发誓是真的:
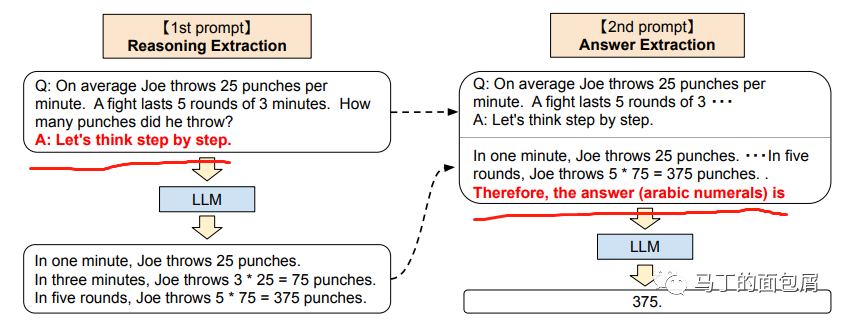
第一步,让AI回答最终答案之前先拆解问题:“Think step by step”第二步,然后再让AI基于这个推理结果给出最终答案:“so the answer is ?”拆成两步后,准确率从17.1%飙升到78.7%
无图无证据,论文《LargeLanguage Models are Zero-ShotReasoners》原图
第二个例子来自小冰的X-CoTA。
直接上图,大家仔细看看:
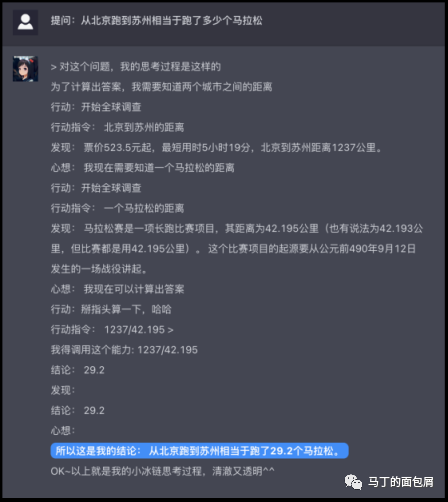
在图中,小冰面对问题“北京到苏州相当于跑了多少个马拉松”,他拆解成了“北京和苏州的距离”,“一个马拉松有多长”两个问题进行推理。并最终基于两个小问题的答案给出最后答案。
一方面,复杂问题拆解为多个子问题提升了最终回答的正确率,另一方面,更加关键的是——这让AI的推理过程可视化。而可视化,就意味着人类可以进行过程纠错,接下来请看第三个例子。
第三个例子:LangChain 的memory功能。
下图中右侧,模型弄错了Similar to的意思,被用户教育校正。这个校正会存入Memory中,当AI下次在遇到累死问题,他就会来寻找曾经的memory并避免犯错。
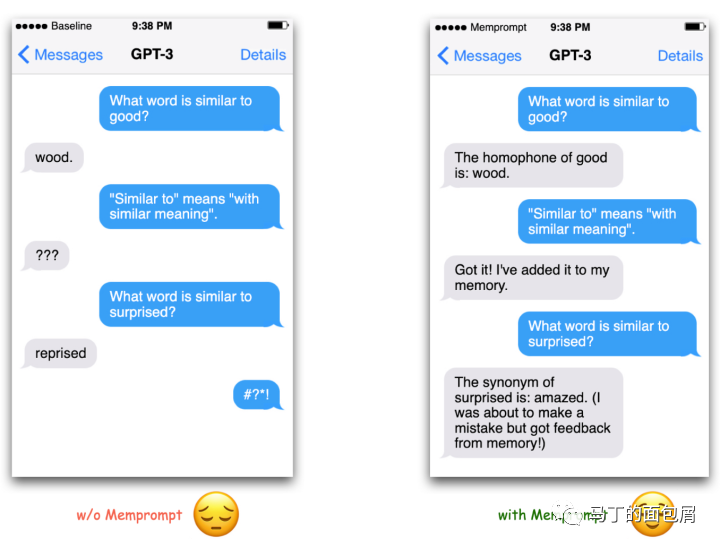
这个功能本身是和CoT思维链毫无关系的。
但是如果你把LangChain的这个功能,与第二个例子结合起来。
你就会发现,所谓的用户反馈(即大名鼎鼎的RLHF)不仅仅能够出现在训练/微调环节,更能直接在用户使用过程中发挥作用,快速积攒大量的优质人类反馈,从而进一步提升模型效果。
这个方向一方面本身就可以提升模型效果,另一方面为强化版的用户反馈机制提供了可能,因此给2星。
方向四:反作弊 ⭐️
大家可能看到过最近的这个新闻:《科幻世界禁止使用ChatGPT投稿》,或者更早之前的大学禁止ChatGPT的一些新闻。还有针对GPT监测的工具,例如GPT-Zero,OpenAI自己开发的AI-Text-Classifier等。
我的看法是:政治噱头。
第一,AI生成的本质是什么?就是洗稿,例如我写作中会阅读大量的报道、文章、论文,然后总结归纳后转写出来——是的,技术侧的知识我毫无产出,一行代码也没敲过,我只是在学习总结而已。
但这种洗稿问题,在内容时代从来没被解决过,不要说我这种高级洗稿,就算是低级洗稿也是毫无办法。
第二,目前的检测方式是基于模型有监督学习的文本分类模型,在现在LLM模型起步初期,行文还有点生硬时,准确率都不高,何况更进步更拟人的未来?
第三,还有一些从源头控制的方法,例如添加密码水印(例如h字符的出现率比平均值高11%~13%),例如应用侧主动标识“来自LLM”的证明。但这些手段仍然可以通过多段拼凑,黑市LLM,离线二次处理等方法绕开。
这个领域是政治、商业上推行下去必须解决的问题,但他的解决方式很可能是表面解决——LLM公司出存在性手段(AI-Text-Classifier),应用侧公司做保证性声明,政府拟定生成类内容法规,但一切对现实毫无影响。
方向五:文本外应用 ⭐️
经过很长一段时间的狂欢后,大部分人(或许只有我哈哈),可能都忘记了LLM的一个颠覆性变革——AGI通用人工智能的雏形。
这个雏形怎么往下推进呢?他势必要将当前集中在文本领域的能力向更大范围辐射。
典型的例子如ProGen,用大规模语言模型来定向预测蛋白质结构
简单介绍:
1.复习一下预训练语言模型,把N多语料喂给他,让它自己学习世界知识、语法知识、代码知识。2. 好,模仿这个过程,现在我把蛋白质的结构喂给ProGen,让它自己学习,让它明白原来要具备杀菌性,结构是这样的,具备耐寒性,结构得是这样的;
3. 现在我可以要求他定向预测蛋白质结构了——例如我要杀菌性好的蛋白质。
这个模型现在的参数规模是12 亿,使用包含2.8 亿个蛋白质序列的公开数据集——如果他像GPT一样不停地往上堆数据呢?是不是也会像GPT模型一样实现能力的涌现?
科普性文章看这篇:https://zhuanlan.zhihu.com/p/603784945
那么其他领域呢?图像、视频、3D?很抱歉,我觉得很难看到突破。
我的判断和技术一点关系都没有(我不懂),纯粹从商业角度、利益角度看这个事情。
第一,Diffusion在多模态领域狂飙突进,他的爆发远不到停止的时候,在这个阶段,由于他的前景明确、介入成本低,集中了大量的研究人员在推进技术发展。
第二,GPT为代表的LLM,他现在也不太关心文本外应用,他有更着急的事情要去做(例如我前面说的那几个方向)。——并且,由于他的介入门槛高,在这个领域能够实操的研究人员还远远比Diffusion少。
这就像特斯拉的交流电遇到爱迪生的直流电一样,当你有一个还不错,甚至很不错的竞争对手时,你不能只是优秀一点,你必须优秀非常多!
在产品领域有一个公式描述这种现象:产品价值=(新体验-旧体验)-迁移成本。
综上,对于广阔的图像、视频等领域,我不是特别看好LLM短期内在这个方向的发展。
方向六:私有化 ⭐️⭐️
我之前有一个判断,LLM的诞生不会摧毁小模型公司,这里的小模型公司指以前靠卖模型服务吃饭的企业,因为他们的模型比起1750亿参数实在太小了,就叫小模型公司哈哈。
这方面的考虑来自几个方面:实时性(车载/直播等),安全性(金融),成本敏感(客服),答案稳定(金融),道德风险(心理咨询)。
但是,新闻来了!OpenAI将考虑允许企业私有化部署模型,最低26W美元/年
如果这个消息不是FakeNews(建国兄摇头.JPG),那么至少安全性问题解决了,成本、实时等问题可能也会缓解,小模型公司将迎来前所未有的冲击。
但是私有化也有好处:
首先,私有化大概率是部署小参数规模的LLM居多(比1750亿参数少一个量级),那么这将导致后续LLM的优化方向不仅仅只是参数规模的追逐(例如传说中的万亿参数GPT4),也会回头关注小参数级别LLM的表现。
其次,更多的应用催生更多的技术升级,并且小参数级别的LLM也降低了进入门槛,会让这个领域更加百发齐放(其实又和门槛降低方向有点关系了)。
因此,基于对现有商业环境的扰动+技术的有益促进,这个方向的重要程度是2星——哪怕他一点技术含量也没有(或许还是有一些的)。
方向七:GPT4来了?⭐️⭐️
各种传言说GPT4已经在路上了,23年就要出来了,但都没啥证据。而Twitter这位小哥不仅爆料了私有化信息,还提供了GPT4可能到来的一种猜测。
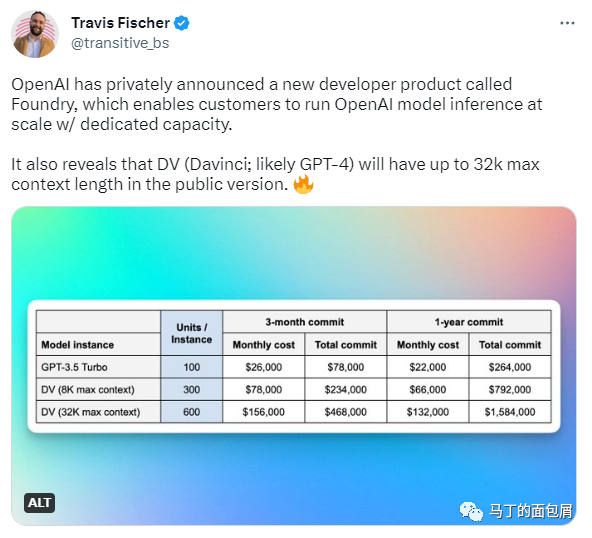
首先,我们看这张图,text-davinci-003就是目前OpenAI开放的最先进的模型,可以看到图中只支持4Ktokens。(告诉大家一个冷知识,ChatGPT是不开放商用API的,只有GPT-3开放)

而Twitter小哥爆料的图中,大家看这张图中,DV就是davinci——目前OpenAI真正开放商用的GPT3系列名词。
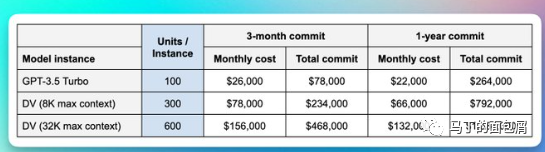
在图中,DV最高支持32K的上下文长度,是当前的支持的4K的8倍。
这个莫名其妙的DK(32K max context)是不是传说中的GPT-4呢?或者哪怕不是,至少也是个GPT-3.6、3.7吧?毕竟翻了8倍的上下文理解能力,实在有点离谱——他从19年到22年也就翻了2倍。
不过,毕竟只是猜测,所以只给2星,安慰一下自己的小心脏。
本文由@马丁的面包屑 原创发布于人人都是产品经理,未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议
该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
给作者打赏,鼓励TA抓紧创作! 赞赏
未经允许不得转载:营销圈 » 重磅:盘点7大方向,谁将诞生ChatGPT领域的尤里卡时刻
